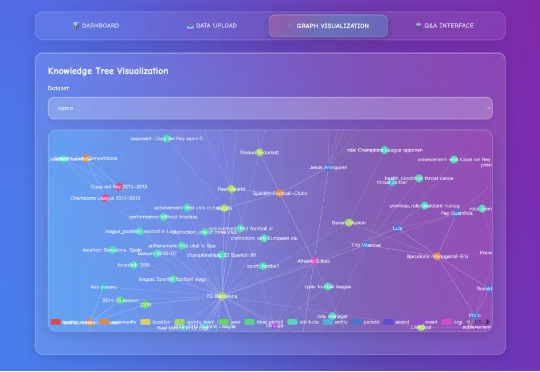
腾讯优图重磅开源Youtu-GraphRAG,实现图检索增强技术新突破
腾讯优图重磅开源Youtu-GraphRAG,实现图检索增强技术新突破图检索增强生成(GraphRAG)已成为大模型解决复杂领域知识问答的重要解决方案之一。然而,当前学界和开源界的方案都面临着三大关键痛点: 开销巨大:通过 LLM 构建图谱及社区,Token 消耗大,耗
来自主题: AI技术研报
9968 点击 2025-09-14 10:45
 搜索
搜索
图检索增强生成(GraphRAG)已成为大模型解决复杂领域知识问答的重要解决方案之一。然而,当前学界和开源界的方案都面临着三大关键痛点: 开销巨大:通过 LLM 构建图谱及社区,Token 消耗大,耗
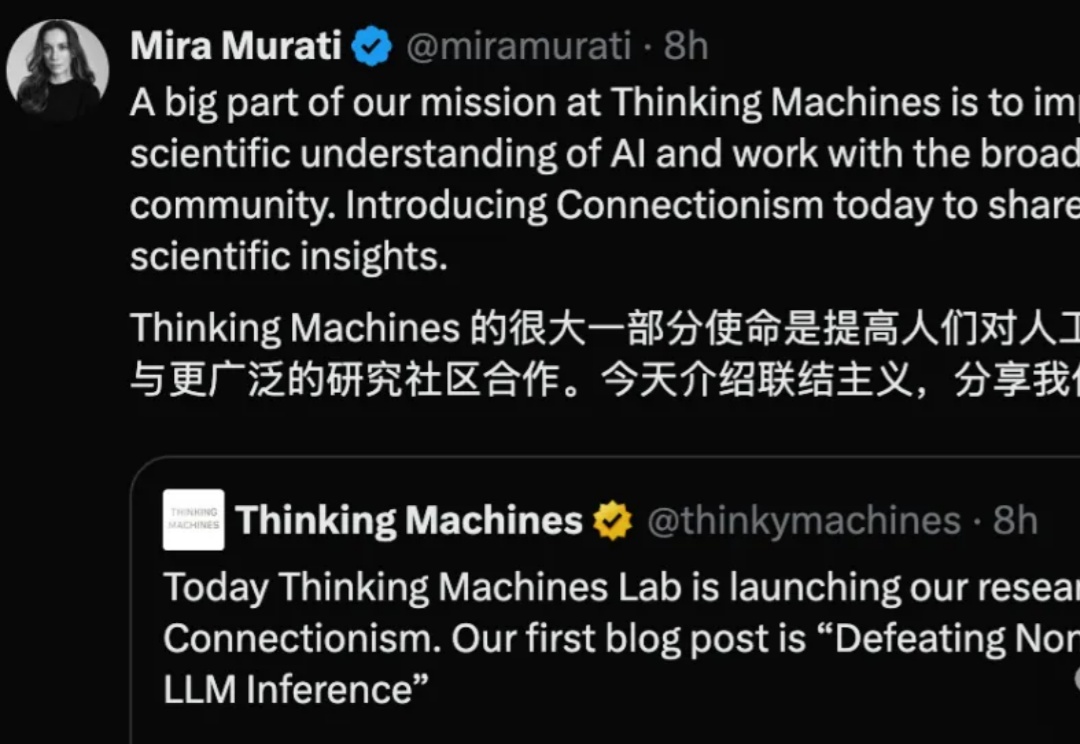
刚刚,0产出估值就已冲破120亿美元的Thinking Machines,终于发布首篇研究博客。

人类心理学说服策略可以有效迁移至LLM 你有没有试过让ChatGPT骂你一句?(doge) 它大概率会礼貌拒绝:私密马赛,我不能这样做orz 但最新研究表明,只需要擅用一点人类的心理技巧PUA,AI就会乖乖(骂你)听话。

记忆,你有我有,LLM 不一定有,但它们正在有。
LLM 似乎可以扮演任何角色。使用提示词,你可以让它变身经验丰富的老师、资深程序员、提示词优化专家、推理游戏侦探…… 但你是否想过:LLM 是否存在某种身份认同?
尽管 LLM 的能力与日俱增,但其在复杂任务上的表现仍受限于静态的内部知识。为从根本上解决这一限制,突破 AI 能力界限,业界研究者们提出了 Agentic Deep Research 系统,在该系统中基于 LLM 的 Agent 通过自主推理、调用搜索引擎和迭代地整合信息来给出全面、有深度且正确性有保障的解决方案。
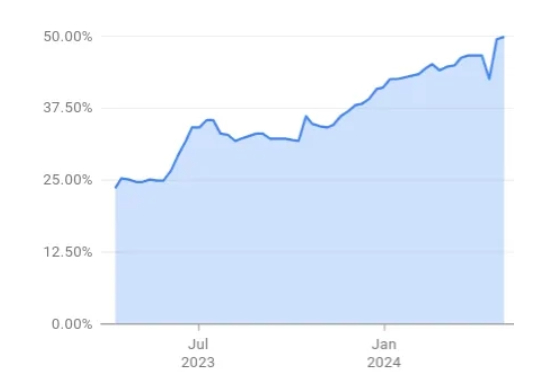
LLM 发展至今,编程能力已经非常强大,成为了很多开发者和软件工程师的「标配」,甚至谷歌还曾宣称其 50% 的代码都是 AI 编写的。
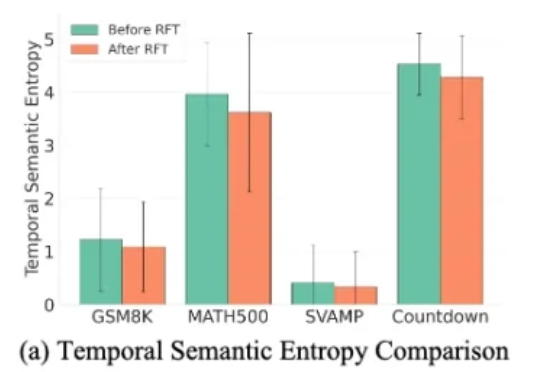
近年来,扩散大语言模型(Diffusion Large Language Models, dLLMs)正迅速崭露头角,成为文本生成领域的一股新势力。与传统自回归(Autoregressive, AR)模型从左到右逐字生成不同,dLLM 依托迭代去噪的生成机制,不仅能够一次性生成多个 token,还能在对话、推理、创作等任务中展现出独特的优势。
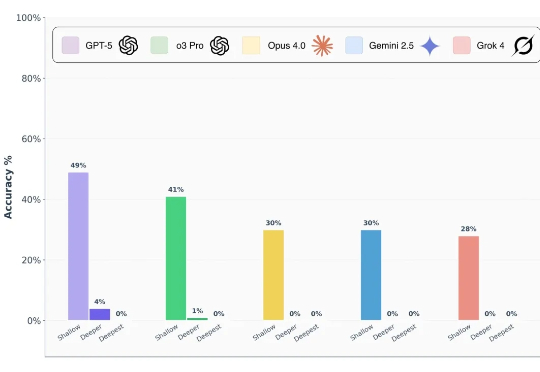
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?

Anthropic 已收购 Humanloop 的联合创始人和大部分团队成员,该公司是一个专注于提示管理、LLM 评估和可观测性的平台,此举旨在强化其企业战略。